Die Scaled Scores des JLPT
Scaled Scores des JLPT
Da Anfang dieser Woche, genauer am 27.08., die Ergebnisse vom JLPT im Juli bekannt geworden sind, wollen wir dir diese Woche die Auswertung und insbesondere das Scoring System des Tests etwas näher bringen. Anders als in üblichen Prüfungen gibt eine Aufgabe im JLPT keine vorher festgelegte Anzahl an Punkten. Stattdessen werden abhängig von deinen Antworten in jedem Teil skalierte Punkte vergeben. Dadurch soll eine fairere Bewertung sichergestellt werden, sodass die Ergebnisse trotz anderer Testfragen über die Jahre vergleichbar bleiben. Also, wenn im Juli 2017 die Fragen generell leichter waren als im Dezember 2017, so müsste man im Dezember entsprechend weniger Fragen korrekt beantworten für die selbe Punktzahl.
Dieser Artikel soll dir die zugrundeliegende Item Response Theory etwas näher bringen. Dabei wird die Bewertung als Wahrscheinlichkeitsproblem aufgefasst. Somit wird es heute etwas mathematischer als zuvor. Zum Bestehen des JLPTs ist dieses Wissen zwar nicht notwendig, aber interessant ist es auf jedenfall.

Es wird heute etwas mathematischer, aber lass dich bitte nicht von den Formeln abschrecken.
Bewertung des JLPT
Wie bereits im vorherigen allgemeinen Artikel zum JLPT beschrieben, geschieht die Auswertung des Tests nach Teilen – Sprachverständnis, Leseverständnis und Hörverständnis. Diese werden auch unabhängig voneinander bewertet (nur in N4 & N5 werden Sprach- und Leseverständnis zusammen bewertet). Bei jedem Teil musst du eine Mindestpunktzahl erreichen und die Summe der Punkte muss einen festgelegten Wert überschreiten.
Nach dem Test selbst musst du allerdings erstmal viel Geduld haben, da die Bögen für die Auswertung nach Japan geschickt werden. Danach erfolgt zuerst eine Bekanntgabe der Ergebnisse über die offizielle JLPT Webseite (engl.) nach knapp 2 Monaten. Anschließend werden die Auswertungsbögen und gegebenenfalls die Urkunden an den Organisator des Tests verschickt und diese leiten die Dokumente dann an die Teilnehmer weiter.
Auf dem Auswertungsbogen findest du unten deine erreichten Punktzahlen, sowie einen Percentile Rank. Dieser gibt an wie viel Prozent der Teilnehmer maximal soviel Punkte erreicht haben wie du und ermöglicht so den Vergleich zu anderen Teilnehmern. Bei voller Punktzahl von \(180\), hast du einen Percentile Rank von \(100\), da alle Anderen höchstens genau so gut waren. Auf der Rückseite findest du außerdem eine Aufschlüsselung der zusammen bewerteten Teile – also Vokabular und Grammatik für das Sprachverständnis. Bei N4 & N5 ist außerdem noch das Leseverständnis im selben Teil. Dabei wird über die Buchstaben A, B und C lediglich grob angegeben wie viel \(\%\) der Fragen du in dem Bereich richtig beantwortet hast. Eine genaue Auswertung, welche Fragen du falsch gemacht hast und Lösungen zu den Fragen, gibt es leider nicht.
Die Grundlage der Bewertung – Die Item Response Theory
Wie zuvor versprochen wird es in diesem Abschnitt etwas mathematischer. Ich versuche zwar die Erklärungen möglichst anschaulich und mit Grafiken zu gestalten, aber wenn Mathe nicht dein Ding ist, spring’ gerne gleich zum Fazit.
Die Item Response Theory (IRT) – auf deutsch die probabilistische Testtheorie – basiert auf der Annahme, dass ein Prüfling eine bestimmte Wahrscheinlichkeit besitzt eine Frage richtig zu beantworten. Diese Wahrscheinlichkeit hängt mit dem Können des Getesteten zusammen. Je höher das Können bzw. Wissen, desto wahrscheinlicher ist es, dass die Frage richtig beantwortet wird. Als Wahrscheinlichkeitsfunktion dient eine Abwandlung der logistischen Funktion \(f(x) = \frac{1}{1 + e^{-x}}\). Diese Funktion stellt eine Kurve dar, die bei \(x=-\infty\) ihr Minimum von \(0\) und bei \(x=\infty\) ihr Maximum von \(1\) erreicht. Während sie zuerst immer schneller steigt, erreicht sie die maximale Steigung bei \(x=0\) und einem Wert der Funktion von \(0,5\).
Bei der IRT wird die Variable \(x\) als Können des Prüflings aufgefasst und die Funktion \(f(x)\) gibt die Wahrscheinlichkeit wieder richtig zu antworten – dabei entspricht die \(1,0\) der \(100\%\). Die Form der Kurve wird bei der IRT außerdem mit mehreren Parametern für jedes Item – bzw. jede Frage – optional ein wenig angepasst. Die üblichen Parameter sind:
- \(a\) Die maximale Steigung der Kurve
- \(b\) Die Schwierigkeit: Verschiebt die Kurve nach rechts bzw. links
- \(c\) Grundwahrscheinlichkeit die Frage richtig zu beantworten (Beispiel: Multiple choice wie beim JLPT. Bei 4 Antwortmöglichkeiten hat man so eine Grundchance von \(25\%\) richtig zu liegen.)
Die entsprechende Formel für ein Item \(i\) sieht dann wie folgt aus:
\(f_i(x) =c_i + \frac{1 – c_i}{1 + e^{-a_i (x – b_i)}}\)
Weil das alles sehr theoretisch klingt und nicht sehr so leicht vorzustellen ist, hier eine kleine Grafik, die die einzelnen Parameter verdeutlichen soll.
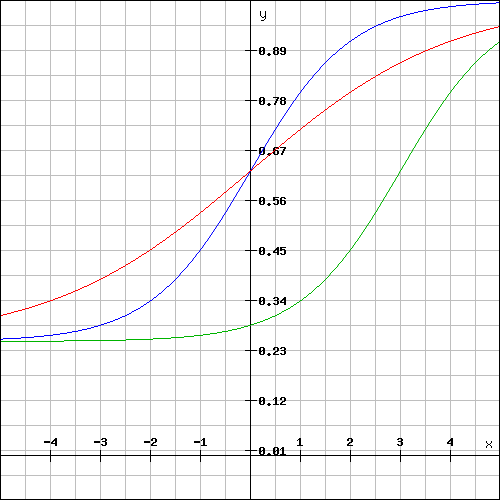
Mit Hilfe der Parameter lässt sich die logistische Funktion verformen. Die blaue Kurve hat lediglich eine Grundwahrscheinlichkeit erhalten, weshalb sie bei 0,25 startet anstatt bei 0. die grüne Kurve wurde als schwerer eingestuft, wodurch sich die Kurve nach rechts verschiebt. Bei der roten Kurve hingegen wurde die maximale Steigung halbiert.
Auswertung der Items und Bestimmung des Wissenslevels
Mit Hilfe von vielen solchen Items \(i\) und den entsprechenden gegeben Antworten lässt sich das wahrscheinlichste Wissenslevel des Prüflings bestimmen. Dafür werden alle Kurven miteinander multipliziert, wobei bei falschen Antworten die Gegenwahrscheinlichkeit stattdessen multipliziert wird, also \(1-f_i(x)\):
\(g(x) = \sum_i{d_i*f_i(x)}\)
\(di=1,0\), bei richtiger Antwort von Frage \(i\)
\(di=-1,0\), ansonsten
Die sich daraus ergebende Kurve kannst du dir als Wahrscheinlichkeit vorstellen, dass jemand mit dem Können x genau die Antworten wie durch d definiert sind gegeben hat. Dementsprechend ist es am Wahrscheinlichsten, dass der Prüfung das Können x besitzt, bei dem die Funktion g(x) ihr Maximum erreicht.
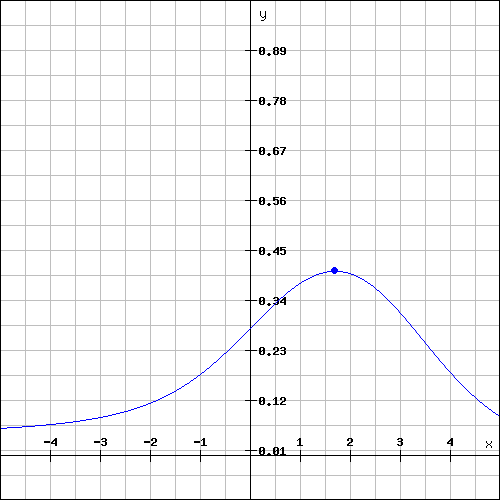
Diese Kurve zeigt die Wahrscheinlichkeit an bei einem Können von x die den oberen Kurven entsprechenden Fragen richtig (blau), richtig (rot) und falsch (grün) zu beantworten. Das Maximum liegt bei ungefähr 1,69 was dem wahrscheinlichsten Können eines Teilnehmers mit diesen Antworten darstellt.
Die Item Response Theory im JLPT
Da wir keine genaue Beschreibung zu den Items im JLPT finden konnten, sind die Angaben hier Mutmaßungen von mir. Die Verweise auf der offiziellen JLPT Seite führen leider nur zu japanischen Quellen (Wenn man die versteht, muss man sich um die Auswertung des Tests wahrscheinlich nicht mehr sorgen 😉).
Höchstwahrscheinlich wird auch für den JLPT die IRT-Variante mit den 3 Parameter gewählt. Dabei lassen sich die Parameter wie folgt auffassen:
- \(a\) Die Verständlichkeit der Frage. Wenn die Frage unverständlich ist, steigt die Wahrscheinlichkeit die Frage richtig zu beantworten nicht mehr so stark.
- \(b\) Die Schwierigkeit der Frage. Je näher das Können von dir an der Schwierigkeit der Frage dran ist, desto mehr Aussagekraft hat die Frage für deine Bewertung.
- \(c\) Grundwahrscheinlichkeit von \(0,25\) bzw \(0,33\) bei \(4\) bzw. \(3\) Antwortmöglichkeiten. Die Wahrscheinlichkeit die richtige Lösung zu erraten.
Außerdem wird die ganze Kurve verschoben, sodass die maximale Steigung zwischen \(0\) und \(60\) liegt – denn das Können \(x\) stellt in diesem Fall deine Punktzahl für den Teil dar.
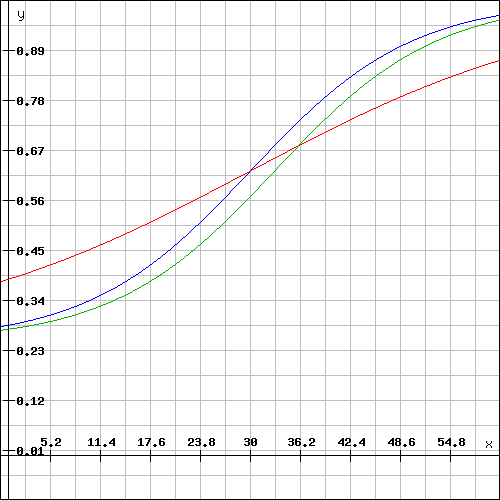
Hier wurden die Item Kurven von oben für den JLPT normalisiert, sodass die Skala nun von 0 bis 60 geht.
Bestimmen der Parameter für die Items
Nun habe ich zwar die ganze Zeit davon gesprochen, dass man die Fragen unterschiedlich bewerten kann mit Hilfe der Parameter, allerdings noch nicht wie man diese erhält. Während die Grundwahrscheinlichkeit \(c\) ziemlich klar ist – durch die Anzahl der möglichen Antworten – sind die Verständlichkeit \(a\) und die Schwierigkeit \(b\) nicht selbsterklärend. Die Bestimmung dieser Parameter ist auch ein Grund warum die Bewertung der Tests so lange dauert. Denn zum Bestimmen der Werte werden alle Antworten von allen Teilnehmern mit herangezogen.
Nach dem Sammeln aller Antworten wird über statistische Auswertung bestimmt wie schwer und wie Verständlich die Frage wohl war. Die Schwierigkeit lässt sich darüber bestimmen, wie viele der Teilnehmer die Frage korrekt beantwortet haben. Für die Verständlichkeit ist es nicht ganz so leicht. Dafür wird geschaut wie die restlichen Antworten der Teilnehmer ausschauen: Hat ein Prüfling, der die Frage korrekt beantwortet hat bei vielen Fragen die korrekte Antwort gegeben? Oder war es eher Zufall, dass die Frage korrekt beantwortet wurde? Und wie viele Teilnehmer haben die Frage falsch beantwortet, aber ansonsten gut abgeschnitten? Diese Auswertung gibt Hinweise darüber, ob die Frage eventuell nur schwer war, weil sie unverständlich war. Durch mindern der maximalen Steigung wird automatisch auch der Einfluss der Frage für deine Punktzahl verringert.
Fazit – was hilft das jetzt?
Tatsächlich lassen sich daraus nicht sehr viele Erkenntnisse ziehen, was wohl die beste Strategie während des Tests ist. Man kann zwar mutmaßen, dass die Fragen weiter hinten eher falsch beantwortet werden bei Sprach- und Leseverständnis aufgrund von Zeitdruck. Somit werden diese Fragen vermutlich als schwer eingestuft. Man könnte nun überlegen den Test von hinten nach vorne durchzugehen. Allerdings gleichen sich falsche leichte Fragen und richtige schwierige Fragen aus.
Wichtig ist allerdings, dass man durch Schummeln – beispielsweise abschreiben oder sonstige Absprachen – nicht nur Auswirkungen auf den eigenen Test hat. Nicht nur, dass die anderen schlechter abschneiden, wenn du mogelst. Wenn du deine richtigen Antworten weitergibst wirst du auch selbst aktiv schlechter. Während es bei anderen Bewertungen keinen Einfluss auf die restlichen Teilnehmer hat, verschlechtert man hier aktiv den Rest. Daher sollte in solchen Bewertungen das Schummeln besonders unterlassen werden!
Schlussendlich noch: Es gibt bei den Antworten nur richtig oder falsch. Das heißt wenn du eine Frage nicht weißt, dann lohnt es sich zu raten. Nichts ankreuzen ist gleichbedeutend mit falsch antworten. Wenn du mehr als eine Antwort auswählst zählt dies auch als falsch.
Persönliche Meinung
Ich persönlich fand es sehr spannend sich ein wenig mit der Bewertung zu befassen. Zwar konnte ich keine bestimmte Strategie finden, um den Test leichter zu bestehen. Dennoch wirkt diese Bewertung auf mich deutlich fairer und vergleichbarer als übliche. Es war zwar etwas frustrierend, dass die Hauptquellen nur auf japanisch verfügbar waren, aber zur IRT konnte ich genug anderssprachige Quellen finden und bin mir ziemlich sicher auch bei dem Rest.
Falls du noch Fragen zur Berechnung hast, schreib‘ mir gerne einen Comment!
 Previous Post
Previous Post Next Post
Next Post

Hallo Moritz,
zunächst einmal vielen Dank für Deine ausführlichen Erklärungen, die ich auch als Nicht-Mathematikerin glaube verstanden zu haben. Bei einem Test mit 180 Fragen/Aufgaben völlig unterschiedlichen Schweregrades muss die Bewertung der Komplexität gerecht werden, dennoch wirft mein heutige Ergebnismitteilung (N5) Fragen auf. Definitionsgemäß zeigt die „Reference Information“ :“how many questions an examinee answerd correctly“, es handelt sich also um den Quotienten der Fragen und nicht um scores, in meinem Falle 77/120 = 64% (was mir subjektiv viel zu wenig erscheint, aber das ist ja bekanntlich nachrangig). Da ich aber in jeder Section mit „A“ abgeschnitten habe, also über 67%, halte ich das Ergebnis für mathematisch unmöglich. Wie kann es sein, dass man in allen 3 Einzelergebnissen (außer Listening) über 67% der Fragen richtig hat, aber in alle 3en gesamt nur 64%?
Hallo Monika,
sorry für die verspätete Antwort. Laut der JLPT-Webseite handelt es sich bei der Angabe der Punktzahl (bei dir 77/120) bereits um Scaled Scores. Dementsprechend kann sich die Prozentzahl richtig beantworteter Aufgaben (durch A, B, C dargestellt) von der Punktzahl unterscheiden.
Auf der Webseite findest du unter 5. ein Bild des Score Reports mit Erklärungen zu den einzelnen Sektionen: https://www.jlpt.jp/e/guideline/results.html